Generative AI for Everyone: Out of the Box Solutions
In diesem Post stellen wir Ihnen zwei Out-of-the-Box-Lösungen für generative KI mit Ihren eigenen Daten vor, die keine Programmierkenntnisse erfordern. Die erste Lösung basiert auf Microsoft Azure und OpenAI und erfordert ein Azure-Konto. Die zweite Lösung ist PrivateGPT, ein Open-Source-Projekt auf GitHub, das on-site ausgeführt werden kann. Abschließend finden Sie einen Vergleich unserer Testergebnisse für diese beiden Ansätze sowie für LangChain (das in unserem vorherigen Blog beschrieben wurde).
Showcase: Building a Digital Marketing Assistant
Unser Ziel
Unser Ziel ist es, einen digitalen Marketing-Assistenten zu entwickeln, der auf einem Frage-Antwort-Systembasiert. Dieses System ist darauf zugeschnitten, Anfragen in natürlicher Sprache zu verstehen und Antworten auf dieselbe benutzerfreundliche Weise zu geben. Die Wissensgrundlage für unseren Assistenten stammt aus 33 spannenden Artikeln über digitales Marketing, die auf dem Cusaas Blog verfügbar sind: Customer Segmentation as a Service.
Um eine nahtlose Integration mit unseren Tools zu gewährleisten, haben wir jeden Artikel zunächst in ein ".txt"-Format konvertiert. Obwohl viele Tools HTML- und PDF-Formate direkt verarbeiten können, werden durch die Konvertierung in das ".txt"-Format mögliche Probleme mit der Kodierung oder dem Zeilenumbruch ausgeschlossen.
Microsoft Azure OpenAI (Cloud-Lösung)
Zuerst bauen wir den digitalen Marketing Assistenten in der Cloud mit Hilfe von Microsoft-Technologie auf.
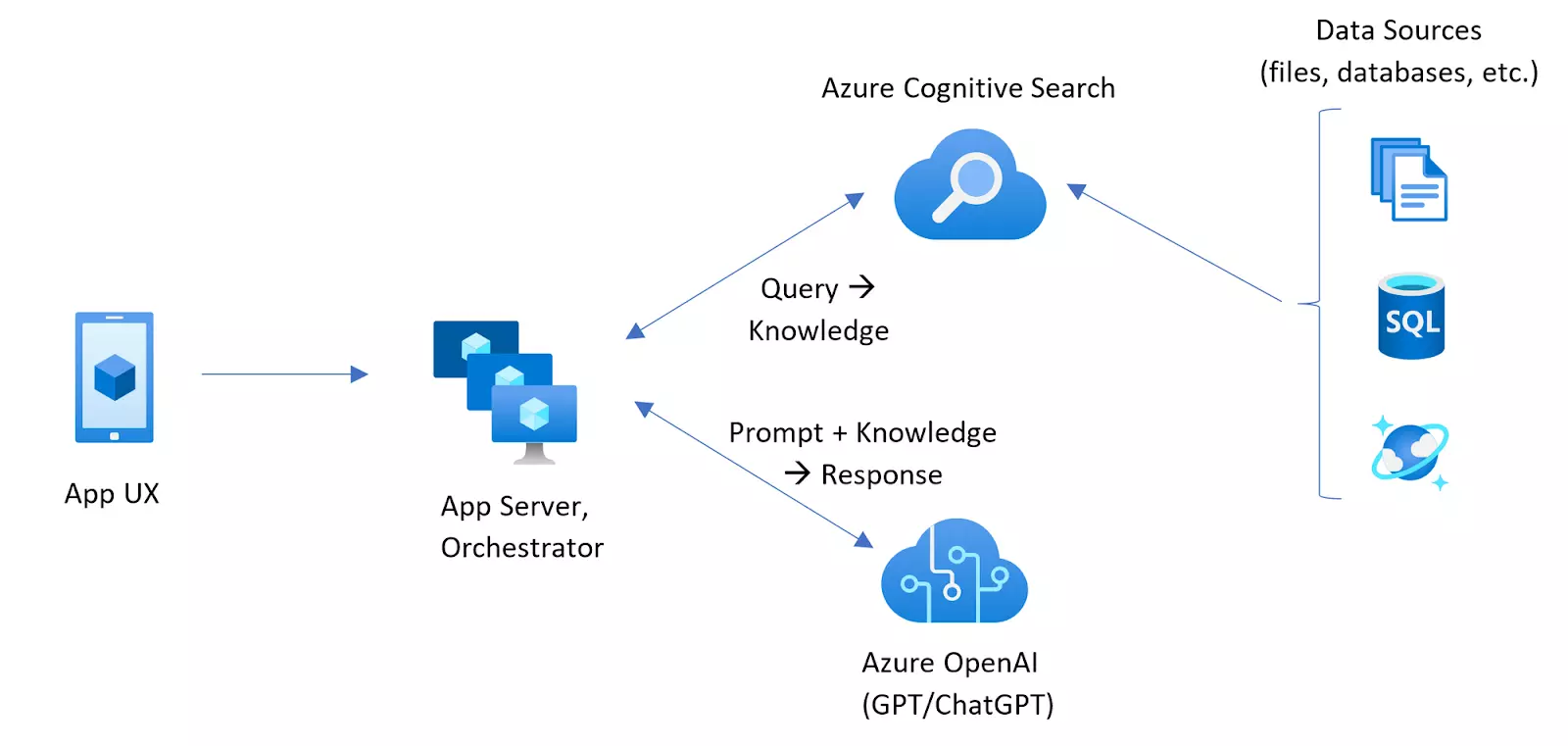
ChatGPT mit MS Azure OpenAI und Azure Cognitive Search[1]
Mithilfe von Azure Cognitive Search und Azure OpenAI Service können wir einen ChatGPT-ähnlichen Chatbot erstellen, der mit unseren Daten in der Azure-Cloud von Microsoft läuft. Dieses Tool kombiniert die besten Funktionen von Azure, hilft bei der schnellen Suche nach vielen Informationen und ermöglicht ChatGPT ganz normal zu chatten.
Eine einfache Möglichkeit, ChatGPT auf Fragen mit unseren Daten antworten zu lassen, besteht darin, ihm gleich zu Beginn die benötigten Informationen zu geben. Das bedeutet, dass ChatGPT Antworten geben kann, ohne dass es neu geschult oder angepasst werden muss. Und es kann schnell neue Informationen verwenden, wenn sich unsere Daten ändern.
Es gibt jedoch eine Grenze, wie viele Informationen ChatGPT auf einmal verarbeiten kann (zum Beispiel kann es nur bis zu 4000 Informationsstücke auf einmal verarbeiten). Außerdem ist es unpraktisch, jedes Mal, wenn wir eine Frage stellen wollen, eine große Menge an Daten zu laden. Eine bessere Lösung ist es, alle unsere Daten an einem separaten Ort aufzubewahren, wo sie organisiert sind und bei Bedarf leicht abgerufen werden können. An dieser Stelle kommt die Cognitive Search ins Spiel.
Tests
Wir haben die nächsten für unsere Tests erforderlichen Schritte durchgeführt:
-
Erstellt einen OpenAI Chatbot mit Hilfe:
- Azure Cognitive Search Service
- Azure OpenAI Service
- Azure Storage Account
- Azure Resource Group
- GPT-3.5 Turbo-Modell wurde als LLM für unseren Chatbot ausgewählt.
- Konvertierte 33 Artikel von Cusaas Blog in das TXT-Format.
- Wir haben unsere Artikel in Azure Cognitive Search hochgeladen und die semantische Suche aktiviert.
- Fragen zu unseren Artikeln wurden eingegeben.
OpenAI Chatbot in Microsoft Azure Open AI Studio sieht wie folgt aus:
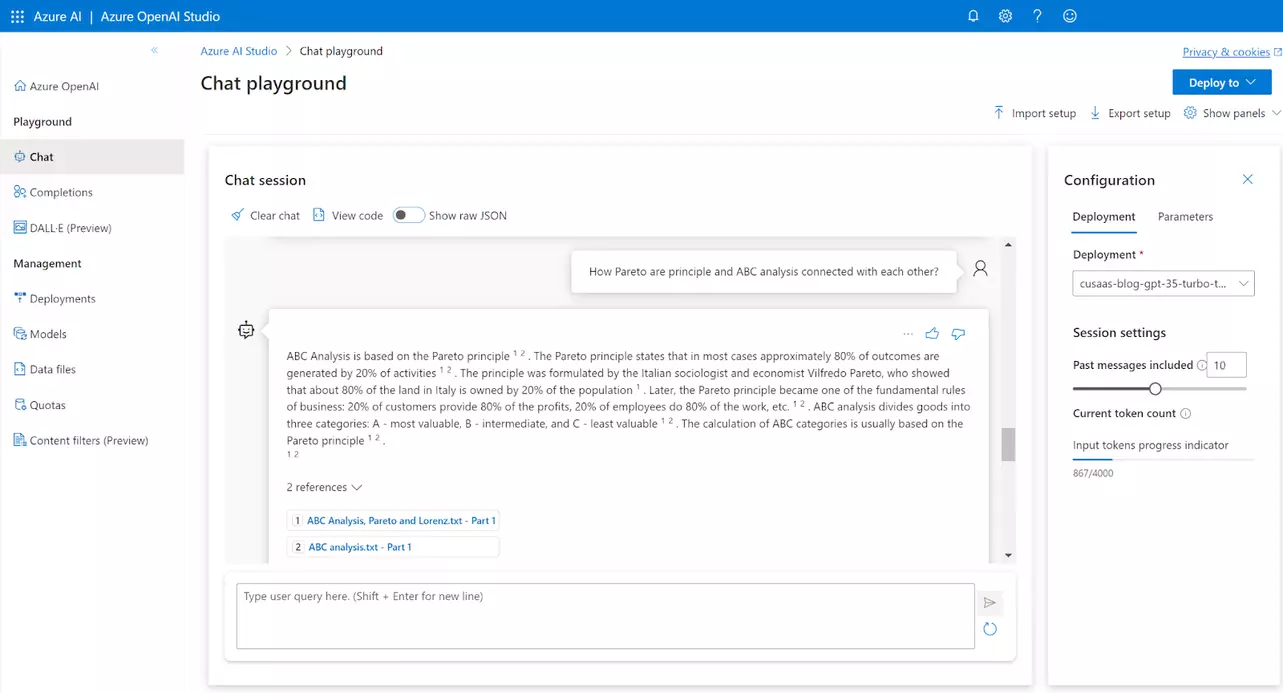
Die finale Lösung wurde deployed als:
- Azure Web Application
- Azure Power Virtual Agent (Chatbot)
Die Testergebnisse finden Sie in der Übersichtstabelle am Ende dieses Kapitels.
Fazit
GPT-3.5 Turbo hat seine Fähigkeit unter Beweis gestellt, genaue und schnelle Antworten zu liefern. Mit GPT-4 erwarten wir eine noch bessere Leistung. Die wichtigsten Erkenntnisse zusammengefasst:
Vorteile:
- Das Einlesen von Dokumenten ist einfach und schnell.
- Der Direktimport ist für häufige Dateiformate möglich: .txt, .md, .html, MS Word, MS PowerPoint und PDF.
- GPT-3.5 Turbo liefert stets präzise Antworten.
- Die Antworten erfolgen in der Regel sofort, wodurch Verzögerungen minimiert werden.
- Das System ist wartungsfreundlich und zuverlässig.
- Da es Teil des Microsoft Azure Stack ist, lässt es sich nahtlos mit anderen MS Azure-Diensten integrieren.
- Die Lösung wird vollständig in der Cloud betrieben.
- Sie generiert auf intelligente Weise Referenzen für jede Aussage.
Nachteile:
- Der Cloud-basierte Ansatz erfordert, dass Microsoft private Daten vertraut werden. Microsoft versichert jedoch, dass die Daten nicht ins öffentliche Internet gestellt oder zur Weiterbildung von LLMs verwendet werden.
- Kostenüberlegungen sind entscheidend. Für Großprojekte mit großen Dokumentenmengen könnte das Preismodell pro Token zu teuer sein.
- Die Modellauswahl ist derzeit begrenzt, da nur die Modelle GPT, DALL-E, Embeddings und Whisper angeboten werden.
PrivateGPT (On-Premises-Lösung)
Hier liegt der Schwerpunkt auf einer On-Premises-Lösung für einen digitalen Marketing-Assistenten, der auf Unternehmen zugeschnitten ist, die mit sensiblen internen Daten umgehen.
PrivateGPT ist ein Open-Source-Projekt auf GitHub, das sich der Erstellung einer vertraulichen Variante des GPT-Sprachmodells zum Ziel gesetzt hat. Die Initiative hinter diesem Projekt ist die Erforschung der Möglichkeiten eines vollständig privaten Ansatzes zur Beantwortung von Fragen unter Verwendung von LLMs und Vector Embeddings. Mit PrivateGPT können Abfragen an Dokumente ohne Internetverbindung gestellt werden, wobei die Stärken von LLMs genutzt werden. Dies garantiert 100%ige Privatsphäre, da die Daten auf die Ausführungsumgebung beschränkt bleiben. PrivateGPT basiert auf mehreren Technologien, darunter LangChain, GPT4All, LlamaCpp, Chroma und SentenceTransformers.
Das Projekt kann unter folgender Adresse aufgerufen werden: GitHub - imartinez/privateGPT: Interact with your documents using the power of GPT, 100% privately, no data leaks
Folgende Dateitypen werden für die Aufnahme von Wissen akzeptiert: .csv, .docx, .doc, .enex, .eml, .epub, .html, .md, .msg, .odt, .pdf, .pptx, .ppt, .txt.
Funktionsprinzip:
- PrivateGPT verwendet LangChain-Tools zum Parsen von Dokumenten und zur Erzeugung von Embeddings on-site mit HuggingFaceEmbeddings (SentenceTransformers). Die Ergebnisse werden dann in einer lokalen Vektordatenbank über den Chrome Vektorspeicher gespeichert.
- Anschließend wird ein lokaler LLM, der auf GPT4All-J (ein Wrapper in LangChain) oder LlamaCpp basiert, verwendet, um Fragen zu verstehen und Antworten zu generieren. Der Kontext für diese Antworten wird mit Hilfe einer Ähnlichkeitssuche aus dem lokalen Vektorspeicher bezogen, um den genauen Kontext aus den Dokumenten zu ermitteln.[2]
Tests
Die Tests wurden mit der folgenden Hardwarekonfiguration durchgeführt: 11th Gen Intel® Core™ i7-11370H @ 3.30GHz mit 16 GB RAM.
Der Testprozess war wie folgt:
- Das PrivateGPT-Projekt wurde von GitHub heruntergeladen.
- Drei Open-Source GGML LLM-Modelle, die zum Testen gedacht sind, wurden heruntergeladen.
- Die Einstellungen von PrivateGPT wurden in der .env-Datei angepasst.
- 33 Artikel aus dem Cusaas Blog wurden in das TXT-Format konvertiert.
- Diese Dokumente wurden über die Kommandozeile in PrivateGPT eingelesen.
- PrivateGPT wurde von der Kommandozeile gestartet, und es wurden Abfragen zu den eingelesenen Dokumenten gestellt.
Die folgenden Screenshots zeigen die Benutzeroberfläche von PrivateGPT auf der Kommandozeile:
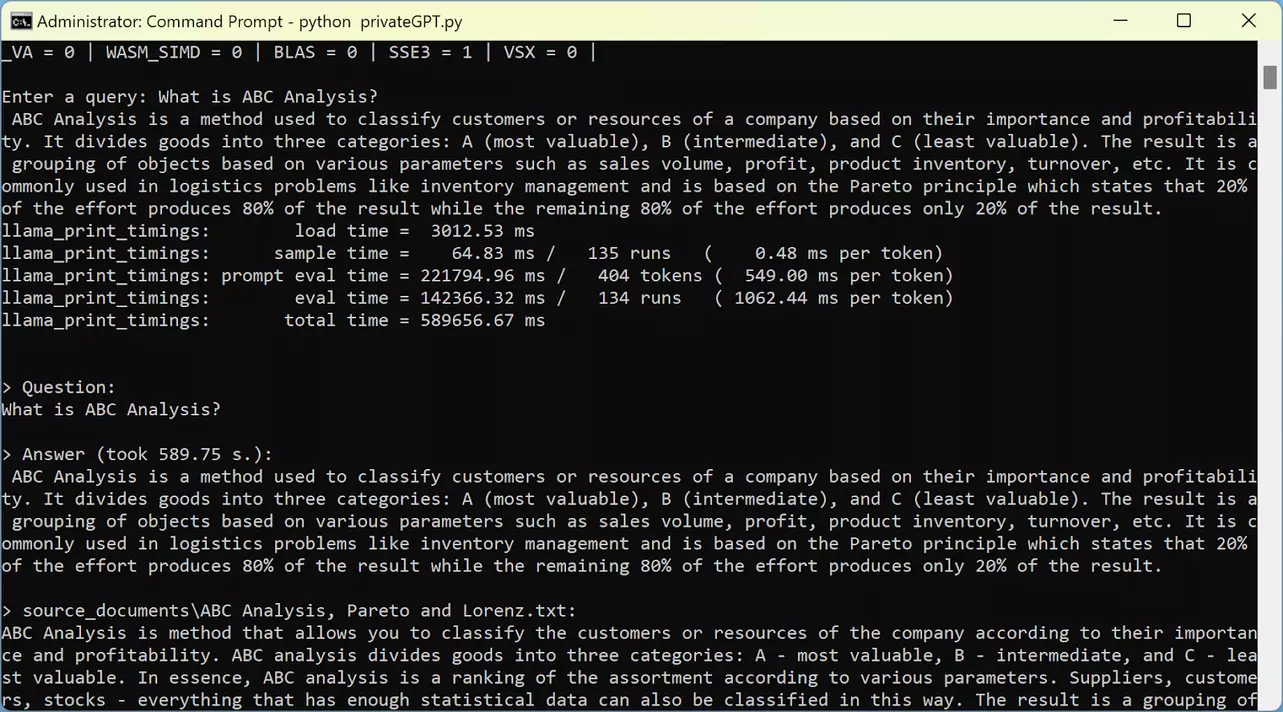
Folgende Modelle haben wir getestet:
- GPT4All (ggml-gpt4all-j-v1.3-groovy): Dies ist das Standardmodell für PrivateGPT. Seine Leistung ist besser als die von Koala 7B, bleibt aber hinter der von Vicuna 13B zurück. Die Qualität der Antworten ist mäßig.
- Vicuna 13B (ggml-vic13b-q5_1): Von den drei getesteten Modellen lieferte dieses Modell die höchste Qualität bei den generativen Antworten. Allerdings ist seine Verarbeitungsgeschwindigkeit im Vergleich zu den anderen Modellen langsamer.
- Koala 7B: Dieses Modell lieferte die am wenigsten zufriedenstellenden Ergebnisse und produzierte Antworten von relativ geringer Qualität. Wir würden es zwar nicht aufgrund seiner Qualität empfehlen, aber es hat den Vorteil, dass es im Vergleich zu den anderen Modellen eine höhere Verarbeitungsgeschwindigkeit besitzt.
Unsere Bewertung zeigt, dass das Modell "Vicuna 13B" (ggml-vic13b-q5_1) die genauesten Antworten auf unsere Abfragen lieferte. Umfassende Testergebnisse finden Sie in der Übersichtstabelle am Ende dieses Kapitels.
Fazit
PrivateGPT eignet sich in seinem derzeitigen Zustand am besten für experimentelle Zwecke und ist noch nicht für die Produktion vorbereitet. Auch wenn es sich noch in der Entwicklung befindet und gelegentlich Fehler aufweist, scheinen die Zukunftsaussichten vielversprechend. Für diejenigen, die eine robustere Lösung suchen, empfehlen wir die kommerzielle Version von PrivateGPT, die von Private AI angeboten wird:
PrivateGPT: The Privacy Layer for ChatGPT by Private Ai
Vorteile:
- Das Hochladen von Dokumenten ist einfach und schnell.
- Es unterstützt eine breite Auswahl an Dokumenttypen.
- Mit dem richtigen Modell (z. B. Vicuna 13B) liefert es äußerst präzise Antworten.
- Der Schutz der Privatsphäre des Nutzers hat Vorrang, da es on-site (lokal auf dem Server) läuft und keine Internetverbindung benötigt.
- Da es Open-Source ist und auf LangChain basiert, ist es kostenlos.
- Es ist vielseitig und kann mit jedem Open-Source-Modell arbeiten.
Nachteile:
- Die Erstellung der Antworten kann sehr zeitaufwändig sein. Bei der Verwendung des Modells "Vicuna 13B" beispielsweise dauerten die Antworten in der Regel zwischen 3 und 5 Minuten.
- Fehlende Unterstützung der GPU-Beschleunigung.
- Die Stabilität kann manchmal ein Problem darstellen, was zu gelegentlichen Fehlern oder Antwortausfällen führt.
- Da es sich um ein Open-Source-Projekt handelt, gibt es keine spezielle externe Unterstützung.
Vergleich der Ergebnisse: MS OpenAI, PrivateGPT, LangChain
Im Folgenden finden Sie eine Vergleichstabelle, in der die drei zuvor beschriebenen Ansätze dargestellt sind:
| What is ABC Analysis? | |
|---|---|
| MS OpenAI GPT-3.5 Turbo 154B | ABC Analysis is a method that allows you to classify the customers or resources of the company according to their importance and profitability. ABC analysis divides goods into three categories: A - most valuable, B - intermediate, and C - least valuable. The calculation of ABC categories is usually based on the Pareto principle, which states that in most cases approximately 80% of outcomes are generated by 20% of activities. ABC analysis is also based on the principle of imbalance, and when it is performed, a graph of the dependence of the total effect on the number of elements considered is plotted. It is called the Lorenz curve. ABC analysis is typically used to track the shipment volume of certain goods and the frequency of call-offs, as well as to classify customers by the number or volume of orders they place. |
| PrivateGPT Vicuna 13B | The Pareto principle is a key underlying concept behind ABC analysis. In fact, the name "ABC" itself comes from the first letters of the three categories that are created through the analysis: A (the most important), B (less important), and C (least important). These categories are determined based on the value or impact each item has on the overall system, which is often measured in terms of its contribution to revenue or profit. The idea behind ABC analysis is that by focusing on the most important items (the A items), a company can improve efficiency and reduce costs while still maintaining a high level of performance. In this way, ABC analysis can be seen as a practical application of the Pareto principle in business management. |
| LangChain LLaMA 2 13B Q6K | The Pareto principle is the foundation for ABC analysis, as it states that 20% of resources (e.g. products, customers, employees) generate 80% of results. This principle is used to categorize resources into ABC categories based on their importance and profitability. |
| How Pareto principle and ABC analysis are connected to each other? | |
|---|---|
| MS OpenAI GPT-3.5 Turbo 154B | BC Analysis is based on the Pareto principle. The Pareto principle states that in most cases approximately 80% of outcomes are generated by 20% of activities. The principle was formulated by the Italian sociologist and economist Vilfredo Pareto, who showed that about 80% of the land in Italy is owned by 20% of the population. Later, the Pareto principle became one of the fundamental rules of business: 20% of customers provide 80% of the profits, 20% of employees do 80% of the work, etc.. ABC analysis divides goods into three categories: A - most valuable, B - intermediate, and C - least valuable. The calculation of ABC categories is usually based on the Pareto principle. |
| PrivateGPT Vicuna 13B | The Pareto principle is a key underlying concept behind ABC analysis. In fact, the name "ABC" itself comes from the first letters of the three categories that are created through the analysis: A (the most important), B (less important), and C (least important). These categories are determined based on the value or impact each item has on the overall system, which is often measured in terms of its contribution to revenue or profit. The idea behind ABC analysis is that by focusing on the most important items (the A items), a company can improve efficiency and reduce costs while still maintaining a high level of performance. In this way, ABC analysis can be seen as a practical application of the Pareto principle in business management. |
| LangChain LLaMA 2 13B Q6K | The Pareto principle is the foundation for ABC analysis, as it states that 20% of resources (e.g. products, customers, employees) generate 80% of results. This principle is used to categorize resources into ABC categories based on their importance and profitability. |
| What do actionable metrics of cohort analysis help to identify? | |
|---|---|
| MS OpenAI GPT-3.5 Turbo 154B | Actionable metrics of cohort analysis help to identify the real situation, make decisions, and improve the business. They are metrics that link repeatable actions to observable outcomes, such as user registration followed by a purchase. By analyzing these metrics across cohorts, companies can better tailor their business to specific customer groups. In the context of customer analytics, actionable metrics of cohort analysis can help identify patterns in customer behavior at different stages of the customer lifecycle. This allows companies to make more informed decisions about how to optimize performance, such as increasing sales or reducing customer churn. |
| PrivateGPT Vicuna 13B | Actionable metrics from cohort analysis can help to identify patterns in customer behavior specific to a particular cohort or group of customers, which can inform better business decisions and targeted marketing strategies for that specific group. |
| LangChain LLaMA 2 13B Q6K |
Actionable metrics of cohort analysis help to identify trends, patterns, and
insights in customer behavior. These metrics can include:
|
Die überzeugendsten Antworten wurden mit GPT-3.5 und LLaMA 2 13B Q6K erreicht. Die Antworten von LLaMA 2 sind tendenziell knapper und präziser. Diese Präzision kann durch Prompt Engineering angepasst werden, so dass man in natürlicher Sprache die gewünschte Länge der Antwort angeben kann, z. B. die Anzahl der Sätze oder Wörter.
Es ist wichtig anzumerken, dass GPT-3.5 Turbo ein proprietäres und ressourcenintensives LLM ist, während LLaMA 2 von Meta vollständig Open-Source, kostenlos und vergleichsweise leichtgewichtig ist. Zum Vergleich: GPT-3.5 Turbo verfügt über 154 Milliarden Parameter, LLaMA dagegen nur über 13 Milliarden. Die Verwendung der LLaMA 2 70B-Version mit 70 Milliarden Parametern kann sogar noch bessere Ergebnisse liefern, erfordert aber deutlich mehr RAM.
Enterprise AI in Action Whitepaper
Danke! Hier ist Ihr Download-Link:
References
- [1] Revolutionize your Enterprise Data with ChatGPT: Next-gen Apps w/ Azure OpenAI and Cognitive Search
-
[2] PrivateGPT:
A Promising Project for Protecting Privacy and Ensuring Data Confidentiality
GitHub - imartinez/privateGPT: Interact with your documents using the power of GPT, 100% privately, no data leaks



