Modelling Complex Mortgage Structures
Why covered bond reporting depends on the underlying data model
Covered bond reporting is often treated as a calculation problem. Take the loan balance, apply the LTV threshold, determine the eligible cover amount, calculate over-collateralisation, produce the report.
In practice, the calculation is rarely the hard part. The harder question is whether the software represents the cover pool correctly in the first place.
That matters because real mortgage cover pools are not flat loan lists. They are networks of borrowers, loans, mortgage liens, properties, valuations, lien ranks, prior charges, allocation rules, eligibility limits, liquidity requirements and reporting obligations. Much of the covered bond logic sits not in the objects themselves, but in the relationships between them.
The four entity classes
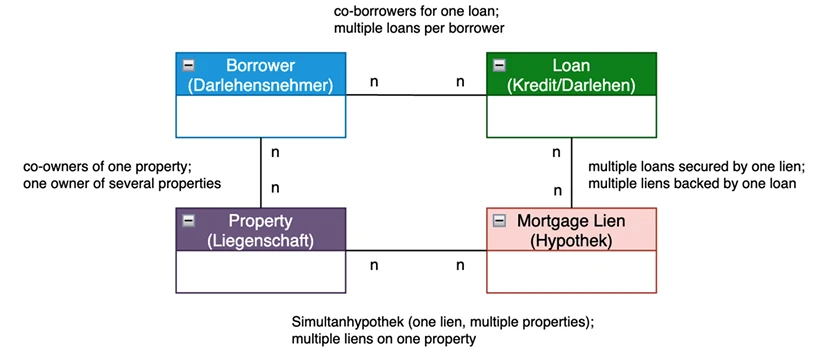
A robust covered bond data model needs to treat four objects as separate first-class entities:
- Borrower — the party or group whose economic exposure is being assessed.
- Loan — the credit obligation, including balance, maturity, repayment profile and eligibility-relevant attributes.
- Mortgage lien — the legal security instrument registered in the land register, with rank, registered amount and secured obligations.
- Property — the real estate asset, with lending value, market value, valuation date, location, property type and eligibility characteristics.
The common shortcut is to collapse the mortgage lien into the loan. That works for the simplest one-borrower, one-loan, one-property case. It fails as soon as the structure becomes realistic: one lien securing several loans, one loan supported by several liens, a simultaneous mortgage lien across several properties, or several liens with different ranks on the same property.
At that point, the distinction between loan, lien and property is not theoretical. It determines how much cover value is available, where it can be allocated, and whether the number can be explained to a cover pool monitor, auditor, supervisor or rating agency.
Relationship Records: Where Covered Bond Facts Actually Belong
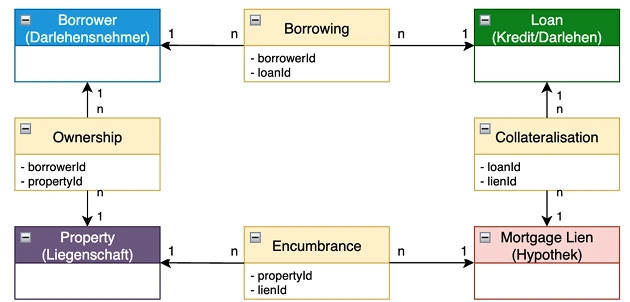
In covered bond software, key information often belongs to the relationship between entities.
Lien rank is not simply a property attribute. It is an attribute of a specific encumbrance on a specific property. Residual capacity for a junior lien depends on the current balance of senior-ranking exposure. Allocation of lending value under a simultaneous mortgage structure belongs to the link between lien and property, not to the property in isolation.
This is why the model needs explicit relationship records — or, in data-modelling terms, junction records. For example:
- Borrowing links borrower and loan.
- Collateralisation links loan and mortgage lien.
- Encumbrance links mortgage lien and property.
- Ownership or economic attribution links borrower and property where needed for aggregation.
These records are where the operational facts belong: lien rank, registered amount, allocated lending value, residual capacity, eligibility status, valuation date, approval status, rule version and audit trail. If those facts sit in comments, attachments or spreadsheets, they cannot be reliably calculated, queried, versioned or audited.
One dataset, different reporting views
Covered bond issuers need several views of the same portfolio.
The regulatory view requires loan-level eligibility: per-property LTV caps, eligible cover amounts, over-collateralisation, haircuts, liquidity reserve, maturity mismatch and asset eligibility. In Austria, the distinction between eligible cover and voluntary over-collateralisation is especially important. A loan can remain in the pool while only part of it counts as eligible cover. One balance field is not enough.
The rating agency view may require borrower-level aggregation. A loan that looks conservative on a standalone basis can look different once all loans and all related properties of the borrower are considered. For commercial mortgage pools, this borrower-level whole-loan LTV can be more meaningful than individual loan LTVs.
Both views should come from the same underlying data model. If regulatory reporting, rating agency submissions and treasury dashboards are produced from separate extracts, reconciliation problems are built into the process.
What goes wrong when the model is too simple
Weak models rarely fail dramatically. They fail through workarounds.
Allocation logic moves into spreadsheets. Residual capacity is calculated from static assumptions instead of live senior balances. Per-property caps are approximated too early. The cover pool monitor asks for a trace from reported LTV to valuation, lien rank and allocation rule, and the answer depends on manual reconstruction.
The result may still be a number. But it is a number that is harder to trust and harder to defend.
For banks, this becomes regulatory risk, audit effort, rating agency reconciliation work and operational dependency on a few people who understand the workaround.
The practical standard for covered bond software
A fit-for-purpose covered bond platform does not need exotic technology. It needs the right abstractions.
It should maintain borrowers, loans, mortgage liens, properties and their relationships as structured, versioned records. It should calculate eligibility at property and loan level, handle rank-dependent residual capacity, support simultaneous mortgage allocation, distinguish eligible from ineligible loan portions, and preserve the lineage of every reported figure.
The point is not to replace legal judgement, treasury expertise or cover pool monitor review. The point is to make sure that this judgement is represented in software in a way that can be applied consistently and explained later.
Covered bonds are legal instruments and funding products. In software, they are also data structures.
The quality of those structures determines whether LTV, eligibility, over-collateralisation and reporting figures can be trusted — and whether the process runs efficiently enough to scale beyond manual reconstruction.



