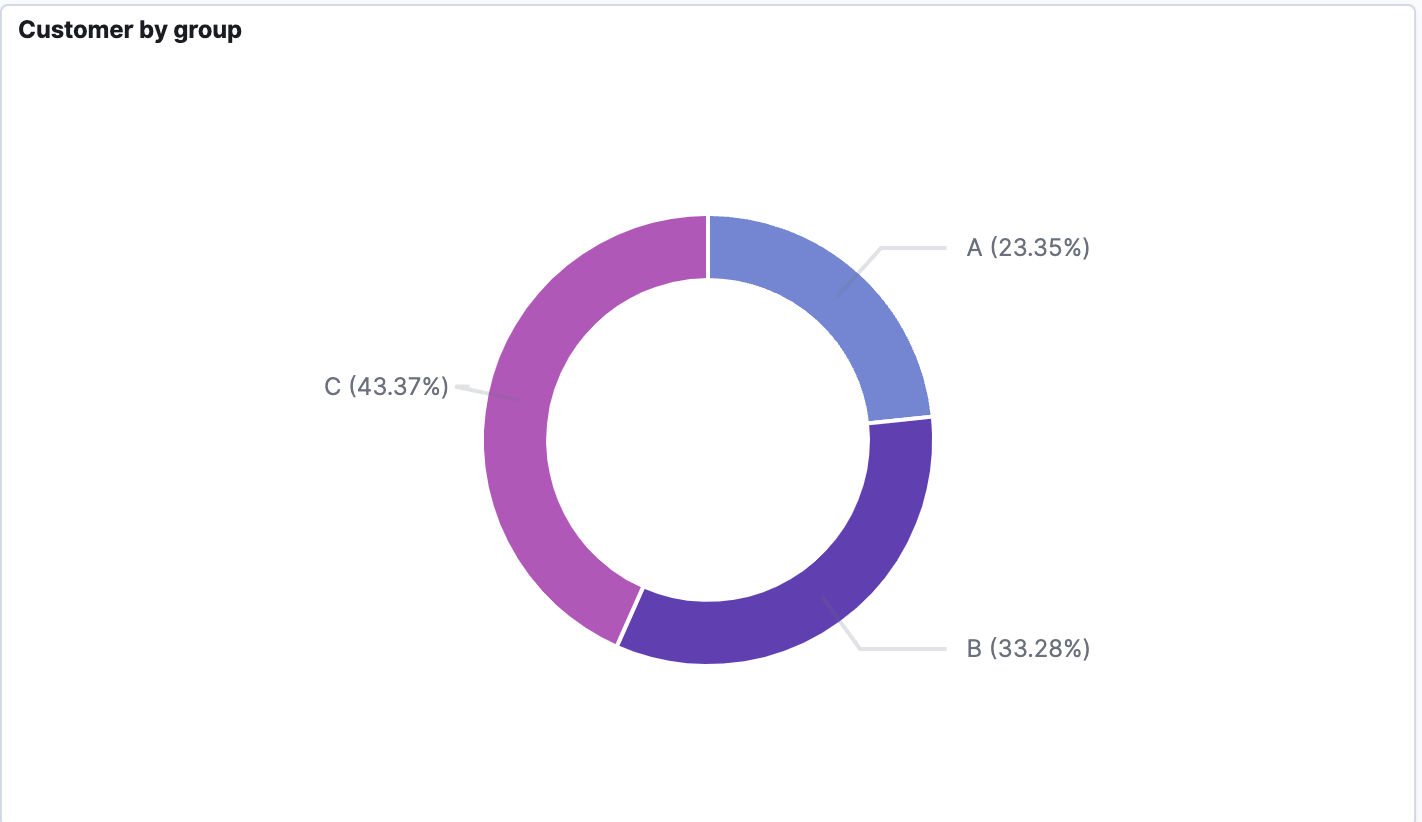
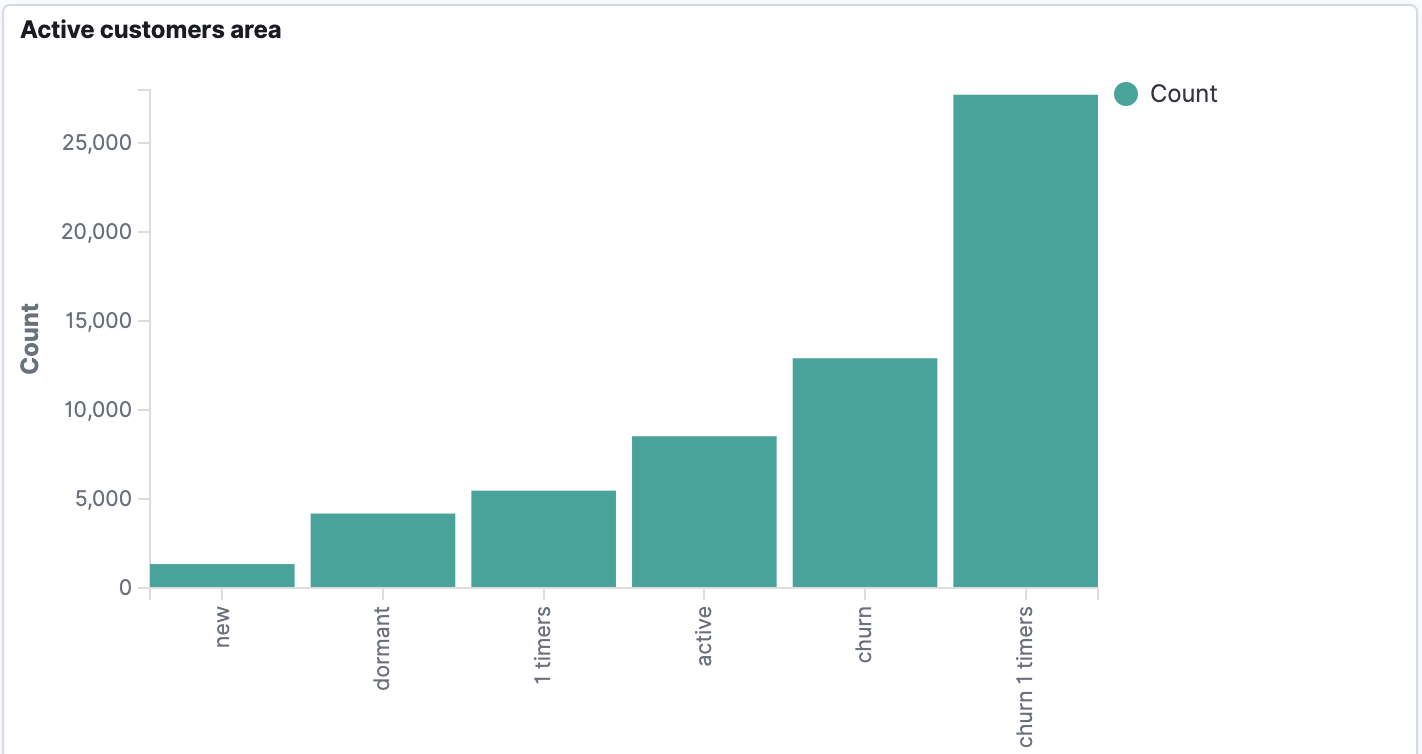
Verwendung von OpenSearch zur Überwachung des Kundenstatus in Echtzeit
Herausforderung: Wir wollen den Zustand der Kunden in Echtzeit überwachen. Es ist möglich, diese Herausforderung mit dem OpenSearch-Stack zu lösen.
Wir haben Daten, die wir im csv-Format analysieren wollen. Die Architektur könnte wie folgt aussehen:
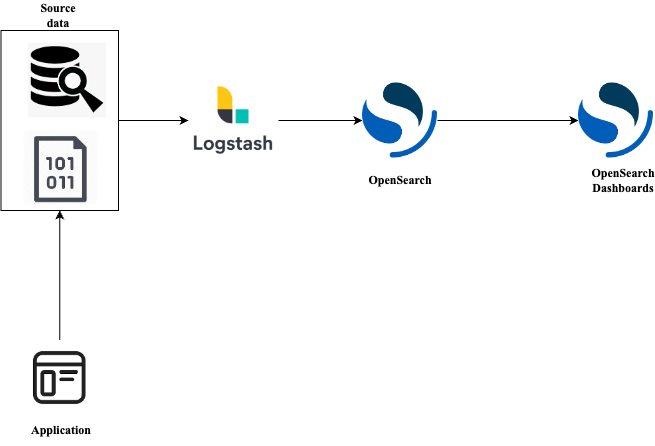
Zum Beispiel schreibt unsere Anwendung kontinuierlich Daten in eine csv-Datei. Wir verwenden Logstash, um diese Daten an unsere OpenSearch-Knoten zu streamen, und verwenden später OpenSearch-Dashboards, um die Daten zu visualisieren und zu analysieren. Und da Logstash für das kontinuierliche Streamen von Daten ausgelegt ist, ermöglicht es uns, einen Einblick in den Zustand der Kunden in Echtzeit zu erhalten.
Was ist OpenSearch?
OpenSearch ist eine Open-Source-Software, die für die Suche, Beobachtung, Analyse und Visualisierung entwickelt wurde. Mit OpenSearch können wir eine Volltextsuche in unseren Daten durchführen, nach Feldern suchen, sortieren und aggregieren. Anschließend können wir unsere Daten mit OpenSearch Dashboards visualisieren. OpenSearch Dashboards ist ein Open-Source-Tool für die Visualisierung und Überwachung von Anwendungsdaten in Echtzeit. Mithilfe verschiedener Grafiken und Diagramme können wir Trends und Muster in unseren Daten beobachten und entsprechend handeln.
Was ist Logstash?
Logstash ist eine Open-Source-Datenerfassung-Engine mit Echtzeit-Pipelining-Funktionen. Mit Logstash können wir Daten aus einer Vielzahl von Quellen an unser bevorzugtes Ziel übertragen. Es ist auch möglich, Daten während der Übertragung zu transformieren, um sie für die zukünftige Visualisierung vorzubereiten.
Diese Technologien ermöglichen es uns, den Client-Status in Echtzeit auf der Grundlage unserer Daten zu überwachen.
Implementierung
OpenSearch ist ein verteiltes System. Das bedeutet, dass wir mit Clustern interagieren, die aus Knotenpunkten bestehen. Ein Knoten stellt einen Server dar, der unsere Daten speichert und unsere Anfrage verarbeitet. Für unsere Demo werden wir einen Cluster mit drei Knoten erstellen: zwei für OpenSearch selbst und einen weiteren für OpenSearch Dashboards.
Für die Bereitstellung unseres Demo-Clusters verwenden wir die in der OpenSearch-Dokumentation enthaltene Beispiel-Docker-Compose-Datei mit einigen Änderungen. Wir fügen einen Logstash-Container zu docker-compose hinzu, der für die Datenaufnahme verantwortlich ist.
1 version: '3' 2 services: 3 opensearch-node1: # This is also the hostname of the container within the Docker network (i.e. <https://opensearch-node1/>) 4 image: opensearchproject/opensearch:latest 5 container_name: opensearch-node1 6 environment: 7 - cluster.name=opensearch-cluster # Name the cluster 8 - node.name=opensearch-node1 # Name the node that will run in this container 9 - discovery.seed_hosts=opensearch-node1,opensearch-node2 # Nodes to look for when discovering the cluster 10 - cluster.initial_cluster_manager_nodes=opensearch-node1,opensearch-node2 # Nodes eligibile to serve as cluster manager 11 - bootstrap.memory_lock=true # Disable JVM heap memory swapping 12 - "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m" # Set min and max JVM heap sizes to at least 50% of system RAM 13 ulimits: 14 memlock: 15 soft: -1 # Set memlock to unlimited (no soft or hard limit) 16 hard: -1 17 nofile: 18 soft: 65536 # Maximum number of open files for the opensearch user - set to at least 65536 19 hard: 65536 20 volumes: 21 - opensearch-data1:/usr/share/opensearch/data # Creates volume called opensearch-data1 and mounts it to the container 22 ports: 23 - 9200:9200 # REST API 24 - 9600:9600 # Performance Analyzer 25 networks: 26 - opensearch-net # All of the containers will join the same Docker bridge network 27 opensearch-node2: 28 image: opensearchproject/opensearch:latest # This should be the same image used for opensearch-node1 to avoid issues 29 container_name: opensearch-node2 30 environment: 31 - cluster.name=opensearch-cluster 32 - node.name=opensearch-node2 33 - discovery.seed_hosts=opensearch-node1,opensearch-node2 34 - cluster.initial_cluster_manager_nodes=opensearch-node1,opensearch-node2 35 - bootstrap.memory_lock=true 36 - "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m" 37 ulimits: 38 memlock: 39 soft: -1 40 hard: -1 41 nofile: 42 soft: 65536 43 hard: 65536 44 volumes: 45 - opensearch-data2:/usr/share/opensearch/data 46 networks: 47 - opensearch-net 48 opensearch-dashboards: 49 image: opensearchproject/opensearch-dashboards:latest # Make sure the version of opensearch-dashboards matches the version of opensearch installed on other nodes 50 container_name: opensearch-dashboards 51 ports: 52 - 5601:5601 # Map host port 5601 to container port 5601 53 expose: 54 - "5601" # Expose port 5601 for web access to OpenSearch Dashboards 55 environment: 56 OPENSEARCH_HOSTS: '["<https://opensearch-node1:9200","https://opensearch-node2:9200"]'> # Define the OpenSearch nodes that OpenSearch Dashboards will query 57 volumes: 58 - ./opensearch_dashboards.yml:/usr/share/opensearch-dashboards/config/opensearch_dashboards.yml 59 networks: 60 - opensearch-net 61 logstash: 62 image: opensearchproject/logstash-oss-with-opensearch-output-plugin:latest 63 container_name: logstash 64 volumes: 65 - ~/Downloads/opensearch-playground/logstash:/usr/share/logstash/pipeline 66 - ~/Downloads/opensearch-playground/data:/usr/share/cussas-data 67 - ~/Downloads/opensearch-playground/logstash.yml:/usr/share/logstash/config/logstash.yml 68 networks: 69 - opensearch-net # We deploy it to the same network as our OpeanSearch nodes 70 71 volumes: 72 opensearch-data1: 73 opensearch-data2: 74 75 networks: 76 opensearch-net:
Wir haben Logstash zu diesem Container hinzugefügt und ihn im selben Netzwerk bereitgestellt. Außerdem müssen wir einige Volumes in den Logstash-Container einbinden:
-
logstash.conf- hier werden wir die Konfiguration unserer Pipeline beschreiben1 input { 2 file { 3 path => "/usr/share/cussas-data/results.csv" 4 start_position => beginning 5 sincedb_path => "NUL" 6 } 7 } 8 filter { 9 csv { 10 columns => [ 11 "Action", 12 "Action_CLV", 13 "CLV_Segment", 14 "CLV", 15 "Cohort", 16 "Period", 17 "Client ID", 18 "First order date", 19 "Last order date", 20 "Transaction count", 21 "Client total sum", 22 "Average order sum", 23 "Dormant time, days", 24 "Lifetime, days", 25 "Interaction time, days", 26 "RFM", 27 "ABC-group", 28 "Order frequency", 29 "Expected order time, days", 30 "Expected order time, months", 31 "Lifetime, months", 32 "Interaction time, months", 33 "Time between 1 and 2 orders, days", 34 "Dormant time, months", 35 "Lifecycle segment", 36 "Previous lifecycle segment", 37 "RFM-segment", 38 "Date" 39 40 ] 41 separator => ";" 42 } 43 mutate { 44 remove_field => [ "message", "path" ] 45 convert => { 46 "CLV" => "float" 47 "Cohort" => "integer" 48 "Transaction count" => "integer" 49 "Client total sum" => "integer" 50 "Average order sum" => "float" 51 "Dormant time, days" => "integer" 52 "Lifetime, days" => "integer" 53 "Interaction time, days" => "integer" 54 "RFM" => "integer" 55 "Order frequency" => "float" 56 "Expected order time, days" => "float" 57 "Expected order time, months" => "float" 58 "Lifetime, months" => "integer" 59 "Interaction time, months" => "integer" 60 "Time between 1 and 2 orders, days" => "integer" 61 "Dormant time, months" => "integer" 62 } 63 } 64 date { 65 match => ["Period", "MM/dd/YYYY"] 66 target => "Period" 67 } 68 date { 69 match => ["Date", "MM/dd/YYYY"] 70 target => "Date" 71 } 72 date { 73 match => ["First order date", "MM/dd/YYYY"] 74 target => "First order date" 75 } 76 date { 77 match => ["Last order date", "MM/dd/YYYY"] 78 target => "Last order date" 79 } 80 } 81 output { 82 stdout 83 { 84 codec => rubydebug 85 } 86 opensearch { 87 action => "index" 88 hosts => ["<https://opensearch-node1:9200",> "<https://opensearch-node2:9200"]> 89 index => "cussas-data" 90 user => "admin" 91 password => "admin" 92 ssl => true 93 ssl_certificate_verification => false 94 } 95 }logstash.conf ist in 3 Abschnitte unterteilt: input, filter, output.
INPUT
In diesem Abschnitt definieren wir die Eingabequelle für unsere Pipeline. In unserem Fall geben wir an, dass wir eine Datei als Quelle verwenden möchten. Wir geben den absoluten Pfad zur Datei, die bevorzugte Startposition und den Ort an, an dem Logstash die Informationen über die letzte gelesene Zeile speichern soll.
FILTER
Hier verwenden wir das CSV-Plugin und geben explizit alle Spalten und Trennzeichen für unsere Daten an. Als Nächstes entfernen wir mit dem mutate-Plugin die von Logstash hinzugefügten zusätzlichen Felder, da wir sie in unserem Fall nicht benötigen. standardmäßig werden alle Spalten als Strings behandelt, und wenn wir einige von ihnen verwenden wollen, z. B. für die Aggregation, müssen wir einige der Felder in geeignete Datentypen konvertieren. Und schließlich konvertieren wir die Felder, die ein Datum enthalten, indem wir das Datum-Plugin mit dem entsprechenden Format verwenden.
OUTPUT
Im Abschnitt output geben wir unser Ziel an, in unserem Fall OpenSearch. Der Abschnitt stdout ist für Debuggingzwecke.
-
logstash.yml- hier deaktivieren wir ecs_compatibility, um einige überflüssige Felder loszuwerden.1 http.host: "0.0.0.0" 2 pipeline.ecs_compatibility: disabled
Seit Logstash 8.0 ist diese Einstellung standardmäßig aktiviert. Wir deaktivieren sie hier, um das Feld zu entfernen, das die gesendete Nachricht dupliziert, um Daten zu OpenSearch hinzuzufügen.
-
results.csv- ist unsere csv-Datei mit den Daten, die wir verwenden wollen
Jetzt können wir folgendes Begehl ausführen, um den Cluster zu starten:
docker-compose -f docker-compose.yml up
Arbeit mit der OpenSearch-Konsole
Jetzt sollte alles funktionieren. Lassen Sie uns zunächst überprüfen, ob unsere Daten in OpenSearch aufgenommen wurden:
http://localhost:5601/ im Browser öffnen und anmelden.
Führen Sie in der Konsole eine Anfrage aus, um zu sehen, dass der Index erstellt wurde:
GET _cat/indices
In der Antwort sollte der Index mit dem Namen, den wir zuvor angegeben haben, erscheinen. Die Antwort könnte wie folgt aussehen:
1 green open security-auditlog-2022.12.15 4xhB1Et6RN6dA9IiJKPGlg 1 1 30 0 366.2kb 174.9kb 2 green open security-auditlog-2022.12.23 _d_9m8jGTcam9iC2UWRhDQ 1 1 894 0 2.7mb 1.4mb 3 green open cusaas-data 6ll_TX8xTLWz6t1Q1LnH8g 1 1 20063 0 12.5mb 6.3mb 4 green open security-auditlog-2022.12.14 7Ku2-bj3TWWVb3d7fmvmSg 1 1 895 0 2.8mb 1.4mb 5 green open security-auditlog-2022.12.24 kczt0RDmSD-rerojNkeTaQ 1 1 462 0 1.4mb 735.6kb 6 green open security-auditlog-2022.12.30 5yEJ4Hw8SxyfcaqNLw4xww 1 1 12 0 200.6kb 166.5kb 7 green open security-auditlog-2022.12.21 CRIdhzm_TnaMHKOnc5X5zw 1 1 68 0 245.6kb 100.8kb
Einfache Suchanfrage:
1 GET cusaas-data/_search/
2 {
3 "query": {
4 "match": {
5 "Lifetime, days": 20
6 }
7 }
8 }
Hier suchen wir nach Daten, bei denen das Feld Lifetime, days gleich 20 ist. Wir können die eingegebenen Daten in der Antwort sehen:
1 {
2 "took" : 11,
3 "timed_out" : false,
4 "_shards" : {
5 "total" : 1,
6 "successful" : 1,
7 "skipped" : 0,
8 "failed" : 0
9 },
10 "hits" : {
11 "total" : {
12 "value" : 18,
13 "relation" : "eq"
14 },
15 "max_score" : 1.0,
16 "hits" : [
17 {
18 "_index" : "cussas-data",
19 "_id" : "XIaSU4UB-xSWDumAfiFp",
20 "_score" : 1.0,
21 "_source" : {
22 "CLV_Segment" : null,
23 "Interaction time, days" : 1204,
24 "Cohort" : 223,
25 "Order frequency" : 4.5,
26 "Dormant time, months" : 38,
27 "Previous lifecycle segment" : "churn ",
28 "RFM-segment" : null,
29 "Dormant time, days" : 1184,
30 "Expected order time, days" : 10.0,
31 "Interaction time, months" : 39,
32 "host" : "f97451f2daab",
33 "RFM" : null,
34 "Period" : "2021-12-01T00:00:00.000Z",
35 "Lifetime, days" : 20,
36 "Transaction count" : 3,
37 "Client total sum" : 645,
38 "Last order date" : "2018-09-04T00:00:00.000Z",
39 "Action" : null,
40 "Average order sum" : 215.073333333333,
41 "Action_CLV" : null,
42 "Date" : "2021-12-01T00:00:00.000Z",
43 "ABC-group" : "A",
44 "Expected order time, months" : 0.0,
45 "First order date" : "2018-08-15T00:00:00.000Z",
46 "Time between 1 and 2 orders, days" : 16,
47 "@version" : "1",
48 "Lifecycle segment" : "churn",
49 "@timestamp" : "2022-12-27T12:33:05.679116927Z",
50 "Client ID" : "D507618",
51 "Lifetime, months" : 0,
52 "CLV" : null
53 }
54 },
55 .......
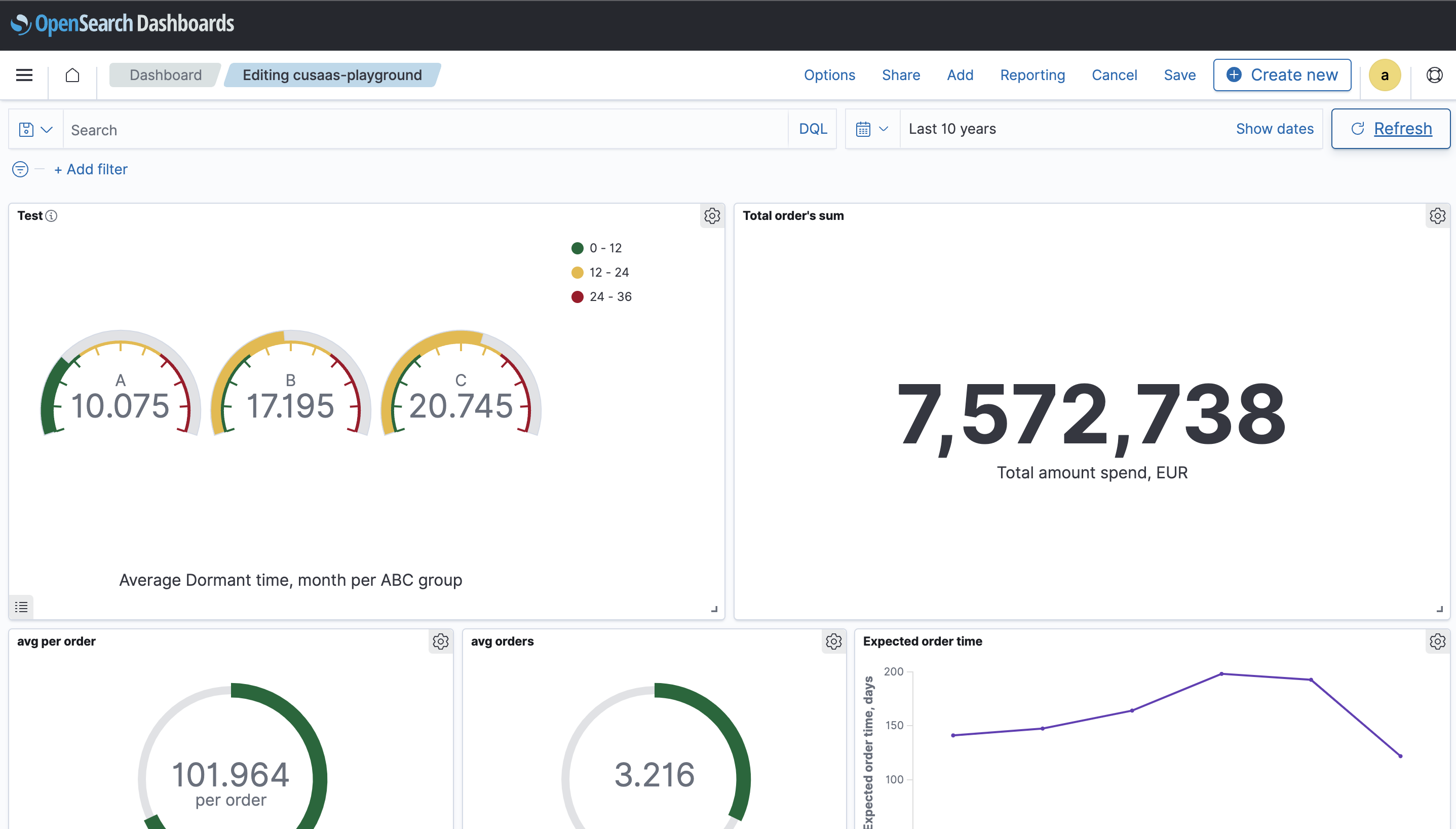
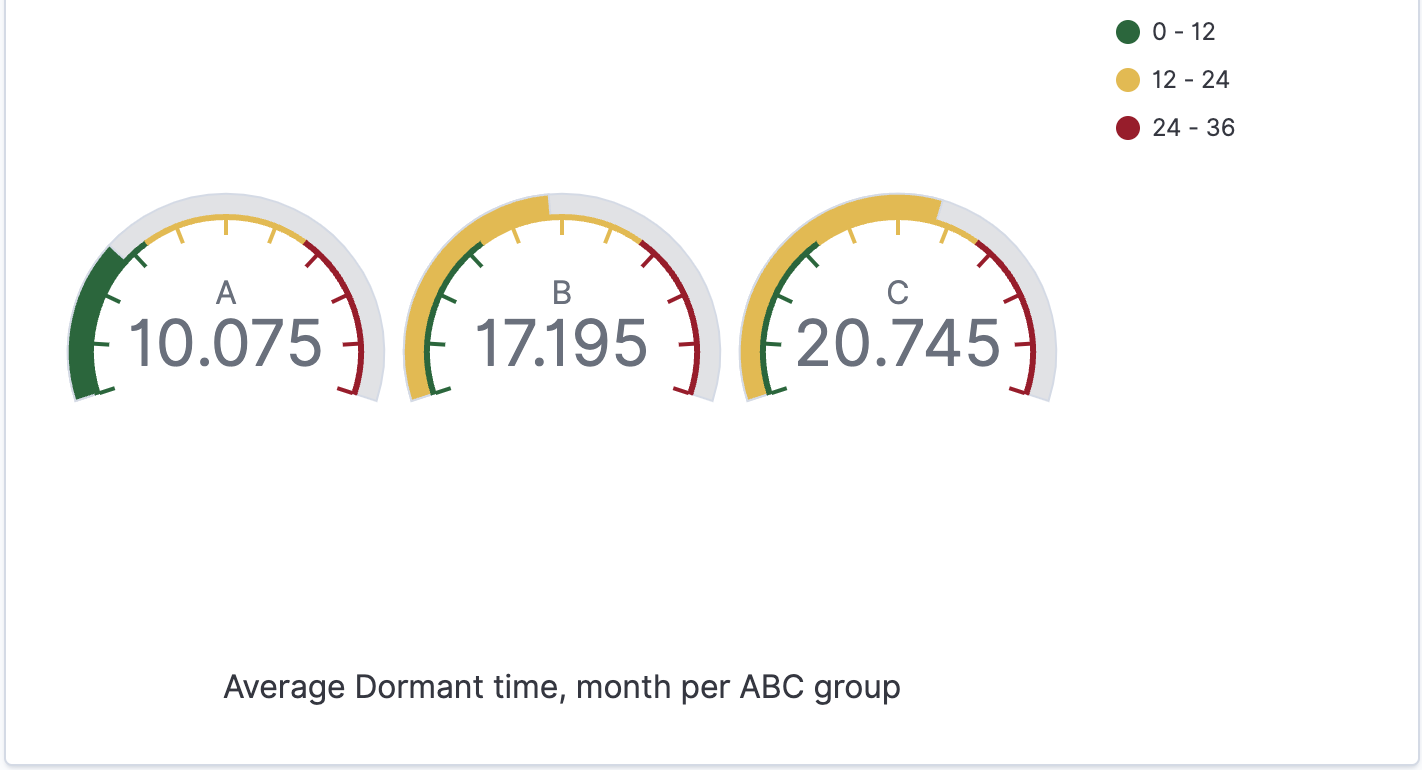
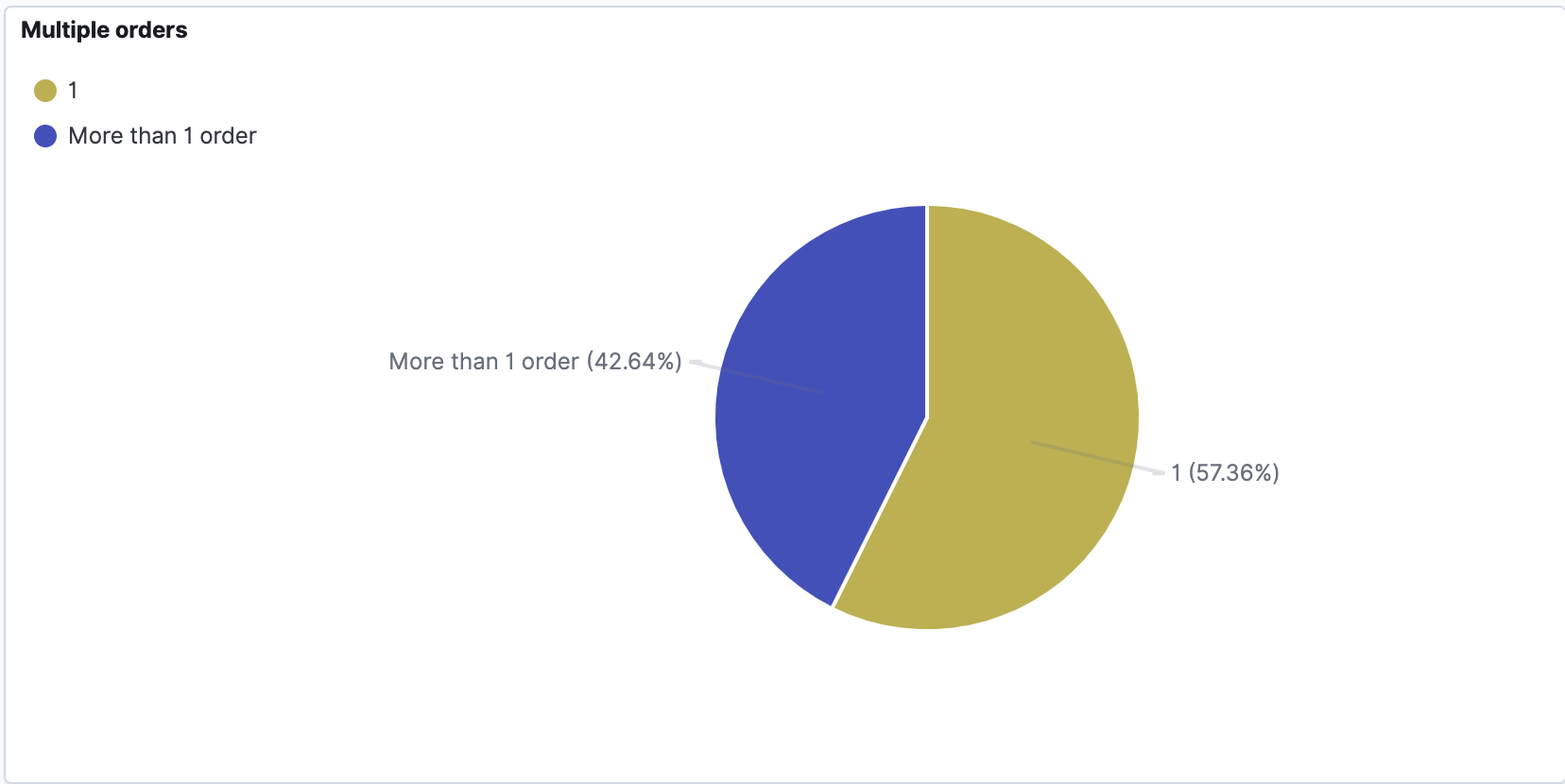
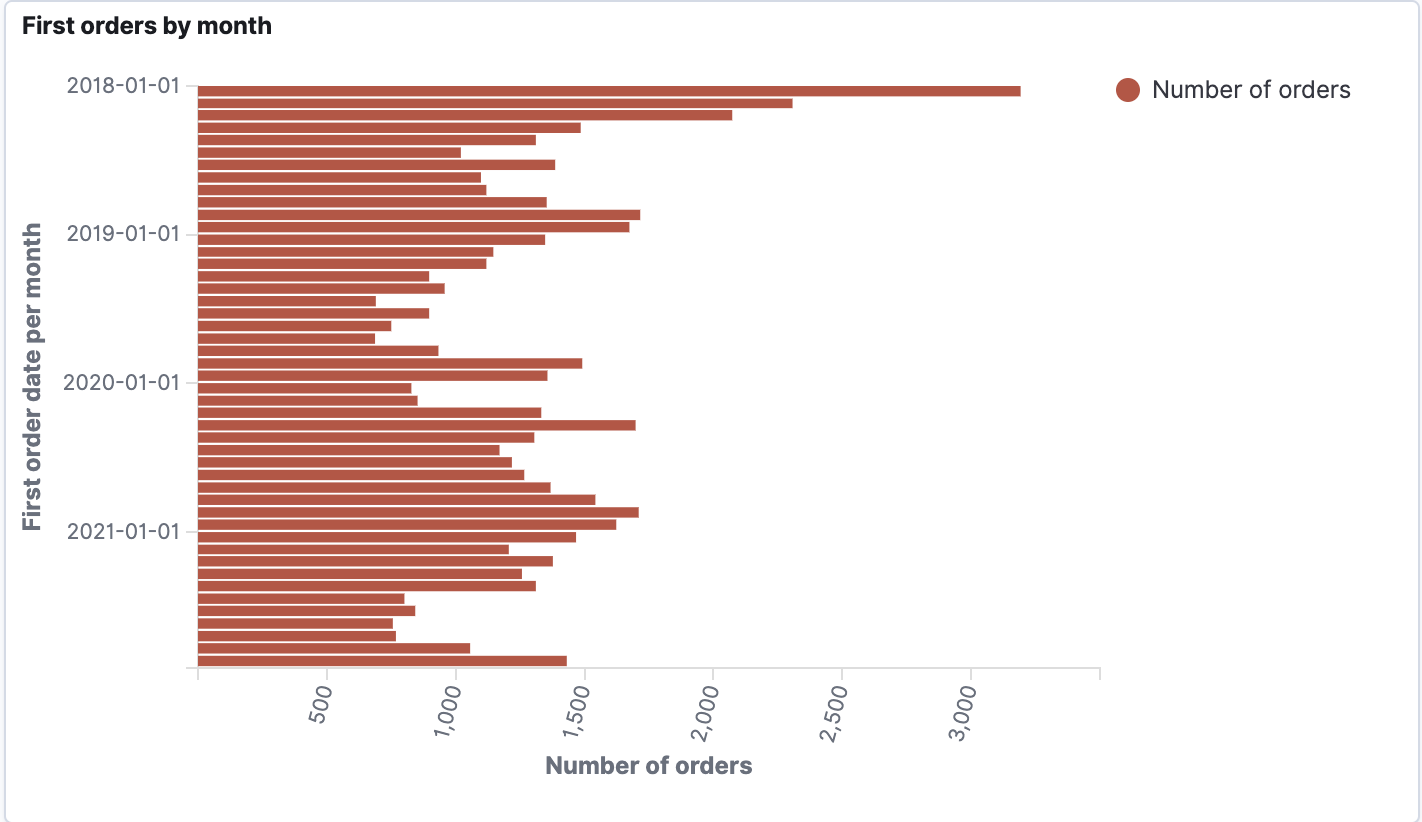
Visualisierung
Um die Daten zu visualisieren, müssen wir zunächst ein Indexmuster für unseren Index erstellen. Auf diese Weise können wir Daten aus verschiedenen Indizes visualisieren, z.B. wenn wir Daten aus verschiedenen Jahren in separaten Indizes mit Jahressuffix haben. (index_name_2020, index_name_2021 usw. können mit dem Indexmuster index_name* verwendet werden). Dann können wir mit der gewünschten Visualisierung fortfahren...