Methodik der Datenanalyse
Bei der Analyse von Informationen kommt es häufig vor, dass die theoretische Brillanz der Analysemethoden mit der Realität kollidiert. Alles scheint schon lange gelöst zu sein, es gibt viele bekannte Methoden zur Lösung von Analyseproblemen. Warum funktionieren sie oft nicht?
Eine theoretisch einwandfreie Methode hat nämlich wenig mit der Realität zu tun. Meistens sieht sich die Analystin/der Analytiker mit einer Situation konfrontiert, in der es schwierig ist, klare Annahmen über das betreffende Problem zu treffen. Das Modell ist nicht bekannt, und die einzige Informationsquelle für seine Konstruktion ist eine Tabelle mit experimentellen Input-Output-Daten, die in jeder Zeile Werte für Input-Merkmale des Objekts und entsprechende Werte für Output-Merkmale enthält.
Infolgedessen müssen alle möglichen heuristischen oder fachlichen Annahmen über die Wahl der informativen Merkmale, die Klasse der Modelle und die Parameter des gewählten Modells getroffen werden. Die Analystin/der Analytiker trifft diese Annahmen auf der Grundlage seiner Erfahrung, seiner Intuition und seines Verständnisses der Bedeutung des zu analysierenden Prozesses.
Die aus diesem Ansatz gezogenen Schlussfolgerungen beruhen auf der einfachen, aber grundlegenden Hypothese der Monotonie des Lösungsraums, die wie folgt ausgedrückt werden kann: "Ähnliche Eingangssituationen führen zu ähnlichen Ausgangsreaktionen des Systems". Die Idee ist intuitiv klar genug, und in der Regel reicht sie aus, um in jedem Fall praktisch akzeptable Lösungen zu erhalten.
Bei dieser Methode der Entscheidungsfindung wird die akademische Strenge der Realität untergeordnet. Das ist in der Tat nichts Neues. Stehen bestimmte Lösungsansätze im Widerspruch zur Realität, werden sie in der Regel geändert.
Ein weiterer Punkt ist, dass der Prozess der Extraktion von Wissen aus Daten demselben Muster wie die Aufstellung physikalischer Gesetze folgt: Sammeln von experimentellen Daten, Organisieren dieser Daten in Tabellen und Finden eines Schemas der Argumentation, das erstens die Ergebnisse offensichtlich macht und zweitens die Vorhersage neuer Fakten ermöglicht.
Es ist klar, dass unser Wissen über den zu analysierenden Prozess, wie bei jedem physikalischen Phänomen, bis zu einem gewissen Grad eine Annäherung darstellt. Im Allgemeinen beinhaltet jedes Schema der Argumentation über die reale Welt Näherungswerte verschiedener Art. Der Begriff Machine Learning bezeichnet neben dem mathematischen auch einen physikalischen Ansatz zur Lösung von Datenanalyseproblemen. Was versteht man unter dem Begriff "physikalischer Ansatz"?
Es handelt sich um einen Ansatz, bei dem die Analytikerin/der Analytiker auf einen Prozess untersucht, der möglicherweise zu kompliziert ist, um mit strengen mathematischen Methoden genau analysiert zu werden. Dennoch ist es möglich, sich ein gutes Bild von seinem Verhalten unter verschiedenen Umständen zu machen, indem das Problem aus mehereren Blickwinkeln angegangen wird, geleitet von Fachwissen, Erfahrung, Intuition und unter Verwendung verschiedener heuristischer Ansätze. Auf diese Weise gelangen wir von einem groben Modell zu immer genaueren Vorstellungen über den zu analysierenden Prozess.
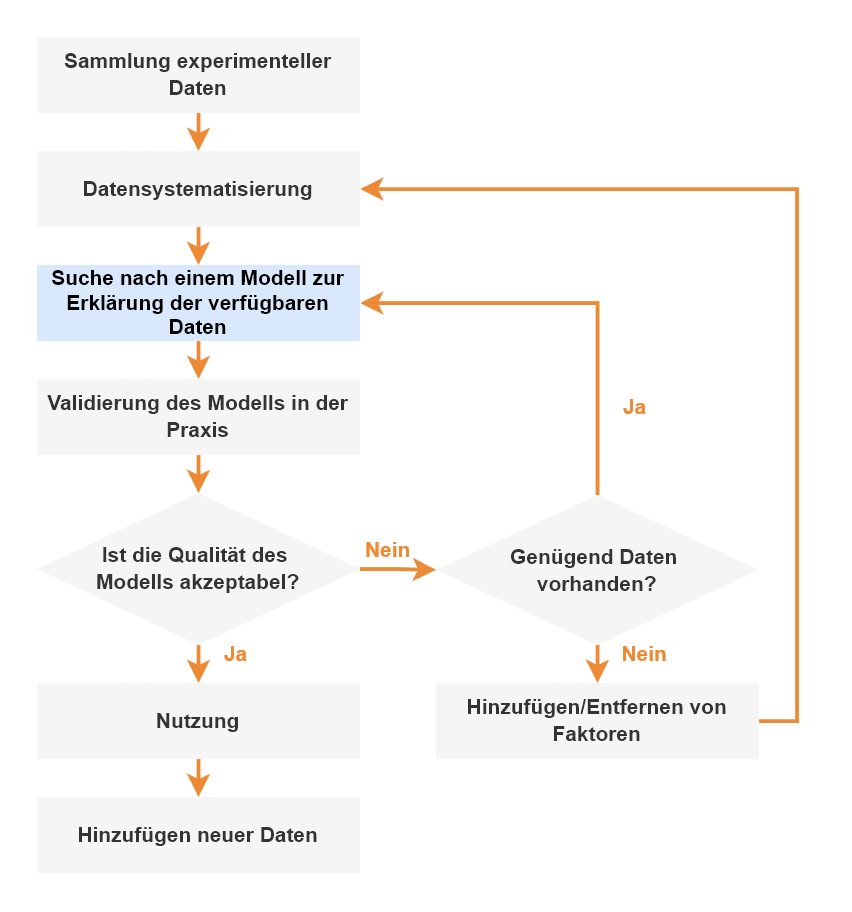
Dieser Ansatz impliziert, dass:
- Die Analyse sollte sich auf das Fachwissen des Experten stützen.
- Es ist notwendig, das Problem aus verschiedenen Blickwinkeln zu betrachten und verschiedene Ansätze zu kombinieren.
- Es ist nicht notwendig, sofort eine hohe Genauigkeit anzustreben, sondern von einfacheren und gröberen Modellen zu immer komplexeren und präziseren Modellen überzugehen.
- Es lohnt sich, aufzuhören, sobald Sie ein akzeptables Ergebnis erzielen, ohne ein perfektes Modell anzustreben.
- Wenn die Zeit vergeht und sich neue Informationen ansammeln, muss der Zyklus wiederholt werden - der Lernprozess ist endlos.
Beispiel
Als Beispiel können wir den Prozess der Analyse des Immobilienmarktes in Frankfurt skizzieren. Ziel ist es, die Investitionsattraktivität von Projekten zu bewerten. Eine der zu lösenden Aufgaben besteht darin, ein Preisbildungsmodell für Wohnungen in Neubauten zu erstellen, d. h. eine quantitative Beziehung zwischen dem Wohnungspreis und den Preisfaktoren zu finden. Für eine typische Wohnung sind dies unter anderem:
- Standort des Gebäudes (unter anderem Infrastruktur des Gebiets; Nachbarschaft des Gebäudes; Ökologie des Gebiets)
- Lage der Wohnung (Stockwerk; Ausrichtung der Wohnung; Blick aus den Fenstern)
- Haustyp
- Größe der Wohnung
- Loggia/Balkon
- Bauzustand (je näher an der Fertigstellung, desto höher der Quadratmeterpreis).
- Verfügbarkeit von Ausstattung ("grobe" Ausstattung, teilweise Ausstattung, schlüsselfertig). Die meisten neuen Gebäude werden mit Rohbauarbeiten geliefert).
- Verkehrsanbindung (Nähe zur U-Bahn, leichte Erreichbarkeit, Verfügbarkeit von Parkplätzen).
- Verkäufer (Investor, Bauträger oder Immobilienmakler).
Zunächst können wir uns aus der verfügbaren Verkaufsgeschichte auf die Daten eines Frankfurter Stadtteils beschränken. Als Inputfaktoren dienen eine begrenzte Anzahl von Merkmalen, die aus der Sicht der Experten offensichtlich den Verkaufspreis von Wohnungen beeinflussen: Ausführung, Stockwerk, Zustand des Objekts, Anzahl der Zimmer, Größe. Das Output-Attribut ist der Preis pro Quadratmeter, zu dem die Wohnung verkauft wurde. Sie erhalten eine recht überschaubare Tabelle mit einer angemessenen Anzahl von Eingabefaktoren.
Trainieren Sie ein neuronales Netz auf diesen Daten, d. h. erstellen Sie ein recht grobes Modell. Das Modell hat einen wesentlichen Vorteil: Sie gibt die Abhängigkeit des Preises von den berücksichtigten Faktoren korrekt wieder. So ist zum Beispiel eine Wohnung im obersten Stockwerk unter sonst gleichen Bedingungen billiger als eine normale Wohnung, und der Preis der Wohnungen steigt mit der Fertigstellung des Objekts. Sie muss dann verbessert und vollständiger und genauer gemacht werden.
In dem nächsten Schritt können die Datensätze von Verkäufen in anderen Stadtteilen Frankfurts zum Trainingssatz hinzugefügt werden. Dementsprechend werden Merkmale wie die Entfernung zur U-Bahn oder die ökologie des Stadtteils als Inputfaktoren berücksichtigt. Es ist auch wünschenswert, die Preise für ähnliche Wohnungen auf dem Sekundärmarkt in das Trainingsset aufzunehmen.
Fachleute mit Erfahrung auf dem Immobilienmarkt haben die Möglichkeit, problemlos zu experimentieren und das Modell durch Hinzufügen oder Ausschließen von Faktoren zu verbessern, da der Prozess der Suche nach dem perfekten Modell auf das Training des neuronalen Netzes mit verschiedenen Datensätzen hinausläuft. Wichtig ist dabei, dass man sich rechtzeitig bewusst macht, dass der Prozess endlos ist.
Dies ist ein Beispiel für einen recht effizienten Ansatz zur Datenanalyse: Die Erfahrung und Intuition eines Spezialisten auf seinem Gebiet werden genutzt, um sich schrittweise einem immer genaueren Modell des untersuchten Prozesses zu nähern. Die wichtigste Voraussetzung dafür ist die Verfügbarkeit von Informationen in ausreichender Qualität, was ohne ein System zur Automatisierung der Datenerfassung und -speicherung nicht möglich ist, was von denjenigen, die sich ernsthaft mit Business Intelligence befassen, stets im Auge behalten werden sollte.
Fazit
Mit dem beschriebenen Ansatz lassen sich reale Probleme mit akzeptabler Qualität lösen. Natürlich hat diese Technik viele Nachteile, aber in Wirklichkeit gibt es keine wirkliche Alternative zu ihr, es sei denn, man verzichtet ganz auf die Analyse. Aber wenn Physiker solche Analysemethoden schon seit vielen Jahrhunderten erfolgreich anwenden, warum sollten sie dann nicht auch in anderen Bereichen eingesetzt werden?



